

- 生成AIという"仕組み"だけではなく、"仕掛け"として捉えることの大切さ -
2023年6月5日'ひと'とITのコラム
画像診断、自動運転、AIカメラで未然防止、ロボット掃除機、・・・と、さまざまな分野でAIの実用化が拡がってきています。その中でも、私たちの身近にあり、最近急速に利用が拡がっているものに対話型AIがあります。生成AIは高い利便性がありますが、その一方で、情報漏えいや著作権侵害などへの懸念といったニュースも耳にします。
今回のコラムでは、OpenAIが提供する「ChatGPT」へのある問いかけを通して、「生成AI(Generative AI)とどう向き合うか?」について語っています。
どうぞコラムをお楽しみください。
(コラム担当記)
巷では、OpenAIの「ChatGPT」、Microsoftの「新しいBing」(ChatGPTの別形)、Googleの「BARD」、Stability AIの「Stable Diffusion」や、iPhoneで「ChatGPT」が使えるようになるなど、「生成AI」の話題で盛り上がっています。ご存じのように生成AIは、文章(テキスト)、画像、音声、プログラムコード、構造化データなどさまざまなコンテンツを生成することが出来るAIとして、従来多かった識別系AI(Discriminative AI)(入力されたデータの正解/不正解の識別)とは区別して定義されています。このうちテキスト生成系のものを「対話型AI」と称するケースもあるようです。すでに使われた方も多いのではないでしょうか。私も流行に乗り遅れまいと「ChatGPT」を試してみました。(掲載の画面はすべてChatGPT-3.5、一部加工しています)
まずは、最近よく困るコラムのテーマ案の候補を訊いてみました〈事例1〉。
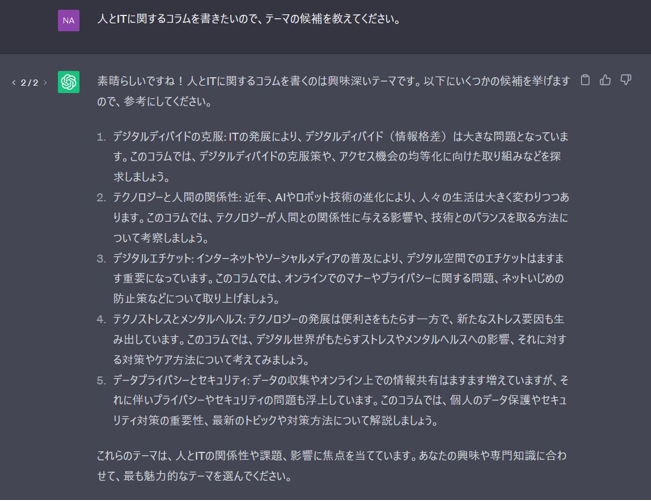
なんと「素晴らしいですね!」と返してきました。人とITに関するコラムを書くのは興味深いそうです。生成AIが対話型AIとも言われているように、自然な会話(高度なチャットボット)はお手のもののようです。テーマの候補案はなるほどという感じです。ちなみに同じ問いを繰り返すと、同じ候補は返さず別物を提案してきます(表示例は回答の左上に2/2とあるように、2回目の答えです)。10回繰り返せば50個候補が集まります。すなわち、候補に優劣をつけて提案してくれているわけではなく、見つかった候補を片っ端から表示しているようです。
次に、前回の第51回コラムの冒頭の話、「H3ロケットの打ち上げに関する文章」を、真実は一つではないと言う観点で約300字に要約してもらいました〈事例2〉。
まず模範解答というわけではないのですが、執筆者である私が要約すると
『2月17日にH3ロケットの打ち上げが行われましたが、メインロケットの点火直前で中止となりました。記者会見の席上、記者と技術者の間で、「打ち上げ失敗」なのか「打ち上げ中止」なのかを巡る論争があり話題となりました。両者の主張は、「打ち上げ直前にメインロケットが点火しなかった」という事実に対し、「ロケットが打ち上がり衛星を軌道に投入出来なかったので失敗だった」という記者の真実と、「不具合があったが打ち上げ中断により安全に停止出来た」という技術者の真実の違いです。真実は事実とは異なり、その前提や視点の違い毎に存在するものであることを、このニュースは教えてくれました。』 というような感じです。ChatGPTは次のような要約を返してきました。

ChatGPTも文章はかなり危ういながら、記者の真実と技術者の真実の違いはしっかり整理しています。ただ、原文では記者と技術者のやり取りは2月17日の1回目の打ち上げ中止後に起きたと書いているのですが、回答では後日(3月7日)修正しての打ち上げ失敗の後に起きたように読み取れます。これは大きな事実誤認で、要約としては致命傷です。
さらにエゴサーチではないのですが、「永倉正洋について教えて。」と訊いてみました〈事例3〉。

なんと、永倉正洋はユニクロを設立したようです。おそらく柳井正氏の内容なのですが、柳井氏は山口県下関市ではなく宇部市出身で、1949年8月29日生まれではなく1949年2月7日生まれです。また、ユニクロの店舗1号店は、1985年山口市ではなく、1984年広島市で開店しています。永倉正洋の情報を(恐らく)柳井正氏の情報を持ってきてしまうだけでなく、ユニクロ創業者(柳井正氏)の情報そのものも不正確さが溢れているかなり"危ない回答"です。
もう一度同じ事を訊いてみました。

今度は、幕末の志士で明治の近代化に貢献したようです。しかも不死身というか生き返ったようで、1864年の禁門の変で一度亡くなったのですが、明治になると政治家として活躍したみたいです。この回答の実際の人物は誰か? 調べてみましたがよくわかりませんでした。ただ、なんとなく近そうなのは木戸孝允(桂小五郎)でしたが、彼は1833年生まれなので微妙です。もしかするとこれは、以前から生成AI全般で観察されている「幻覚症状(hallucination)」によって全く架空の人物が提示されているのかもしれません。
蛇足ですが、永倉正洋について、ChatGPTと同じAIエンジン(ChatGPT-4)を使っているMicrosoftの「新しいBing」でも訊ねてみました。「新しいBing」は、『より創造的に』、『よりバランスよく』、『より厳密に』というように情報の精度と創造性の重みを3段階で指定出来ます。最も精度を重視した『より厳密に』では100%正確な情報を返してきました。『より創造的に』でも骨格は精度が高く、枝葉の部分で"おかしい内容(ちょっと盛ったな!)"が含まれていました。人が成長する過程で学習内容が異なれば、各人異なる個性や能力を発揮するように、生成AIも同じAIエンジンを使っていたとしても、学習の方法で特徴が異なるということです。これは生成AIとの付き合い方を難しくする要因のひとつと捉えることが出来そうです。
さて、試してみたChatGPTでの例をいくつか紹介しました。これらを見て、どのように感じましたか?〈事例1〉見ると、結構使えそうな印象です。〈事例2〉の要約はどうでしょうか?そのままでは使えそうもありませんが、要点を引っ張り出すには参考にはなりそうです。〈事例3〉は・・・これはまったく使いものにはなりそうもありません。せめて「永倉正洋なる人物は知りません!」と回答してくれた方が、よっぽど役に立ちます(?)。ちなみに、ChatGPTは2021年9月までの情報で学習しています。なので例えば、昨日の野球の試合結果をたずねても「2021年9月までの情報しか持っていないので回答できません」と返してきます。
今回のコラムでは、ChatGPTをはじめとする生成AIの精度評価を行うつもりはありません。精度は、現状多くの生成AIが英語圏での学習が深いので、日本語圏での精度はまだ落ちると言われています。ということは、この先日本語での学習が進めば、自ずと精度は高まってくるでしょう。精度が高まれば当然使われるシーンは拡大することは避けられません。ではこのような中では、どのような「生成AIとの向き合い方」が求められるのでしょうか?
先ほどの〈事例1〉で、「素晴らしいですね!」と返してきました。しかしChatGPTは「素晴らしい」という気持ちは持ち合わせていません。そもそも生成AI(テキスト生成系)は何を学習しているのか?情報そのものを知識として学習すると同時に、人間と出来るだけ自然な会話(対話)が出来るように「文章生成能力」を高めています。この時に言葉に潜む"気持ち"まで理解することは出来ません。自然な会話のために、「この言葉の後にはこの言葉が使われることが多い」的な学習を、膨大な情報から学んでいます。ですので"素晴らしいですね!"は褒めているつもりは全くなく、「このケースでは"素晴らしい"という言葉が使われていることが多いから使っている」だけです。世の中に存在する"人が作った文章"は、ほとんどが気持ちと裏腹な言葉の使い方になっています。ただし、"素晴らしい"という言葉に込める気持ちは必ずしも「褒める気持ち」とは限りません。場合によっては「単なる社交辞令」「皮肉」のケースもあります。このように込められている気持ちを抜きにして"素晴らしい"という言葉を"語順の可能性の高さ"だけで学習すると、結局気持ちの部分は相殺されてしまうので、文章全体で中立的な(気持ちを感じさせない)ニュアンスとなることは想像できます。今年になって生成AIが作成したエントリーシートが話題となりました。この話題の中で、採用側から「平坦な文書」「熱意が伝わらない」「気持ちを感じない」というような意見が多かったのも頷けます。ここでやっかいなのが、生成AIが「限りなく自然な会話」が出来てしまうことです。我々は、もし相手の発出する文章が自然ではなく機械的(?)であれば、言葉や文章から気持ちを察しようとはしないでしょう。自然≒人間的であればあるほど、気持ちを勝手に推測してしまいます。すると対話は成り立ってもコミュニケーションは成り立たない状態が起こりえます。これは危険です。いくら自然な会話が出来たとしても、Generate by AIを常に意識することが必要でしょう。
生成AIの課題として、先般のG7 広島サミットでも話題となり、多方面で議論が進められていることのひとつに「プライバシーや著作権侵害のリスク」があります。特にEUではプライバシー保護の観点からかなり慎重な対応となりつつあります。さらにマスコミでは特に画像生成AIでの問題がよく取り上げられています。自分の作風に似た画像(絵画)が生成AIで勝手に作られていることで、著作者の権利が侵害されているというものです。同様の懸念が絵画だけでなく、音楽、脚本、デザイン、コピーライターなど多くの職域で拡がっています。確かに大きな問題であることは間違いありません。しかし、これは生成AIの問題ではない気がします。現在、生成AIが学習する情報からプライバシー・著作権に関わる可能性があるものを除外すべきとの論調も見られます。ここで忘れてはならないのが、我々人間が学習するときにもプライバシーや著作権に関わる情報を使ってきていることです。子どもの頃から本を読む、多様な絵画作品を鑑賞する、さまざまな音楽を聴くなどを通じて「読む力」「書く力」「画く力」「聴く力」「作る力」を獲得し高めてきています。出来るだけ多様な作品に触れることが望まれます。実は生成AIの学習も人間の学習と基本的には変わらないということです。違うのは、人間の学習よりも格段に速く、格段に膨大で、格段に多様だということです。学習の結果、人間も他の著作物に似た作品を創造することが出来ます。絵画の世界では、その到達領域が"贋作"でしょう。"贋作"は、見た目だけでなく、絵の具の材質・経年変化(劣化)、キャンバスに潜む埃までも似せることで、"本物"をめざしています。そこまでいかなくても、「岡本太郎の『森の掟』に似せた絵を描いて」と頼めば描ける人はいるわけです。描けてもそこに著作権侵害の恐れがあれば、それを無造作に発表したりネットに掲載したりはしません。それを禁ずる法律などの規則や認めない文化が存在しています(守らない人がいることも現実です)。しかし学習の段階では禁じていません。著作権も通常は個人利用は許容しています。すなわち、他人の著作権を侵害する可能性がある能力そのものに歯止めをかけているわけではなく、創造物の利用の段階で著作権を侵害するかどうかで判断しています。ということは、生成AIが学習する段階に歯止めをかけるのではなく、生成AIが生成する段階、もしくは生成した作品を活用する段階で歯止めをかけるのが利に適ったやり方のように思えます。では、この歯止めをかけるのは誰か?ある程度生成AI自身が歯止めをかける仕組を持つことも可能でしょうが、基本的には生成AIに依頼する側、すなわち利用者(=人間)が歯止めをかけるのが筋です。完全な自動運転が実現したときに起きた事故の責任は誰か? と同じロジックです。従来の人間だけの生成環境の"仕掛け"と、人が生成AIを活用する環境の"仕掛け"は、特段変わりないし変えてはいけないのかもしれません。
先ほどの〈事例2〉〈事例3〉からもわかる通り、生成AIは今のところ検索は苦手だとも言われています。ただこれは今後日本語の学習が進めば精度は高まると思いますが、現状英語圏版でもそこそこの頻度で誤認が発生していることを考えると、完全に正しい検索は難しいと考えるのが妥当でしょう。特に、わかっていることを訊いた場合は確からしさを確認できますが、わかっていないことを尋ねる場合はかなりリスクがあります。しかも、自然な文章で返されると人は騙されやすい。それでは検索の場面(明示的に検索でなくても文章生成などで検索結果が使われる場面も含め)で、生成AIとどのように向き合えばいいのか?私は「動的なWikipedia(ウィキペディア)」と捉えています。Wikipediaはみなさんもよくご存じで使われている方も多いと思います。便利ですよね。通常のネット検索と何が違うのか。知りたいことが分かり易く書かれていることでしょう。これはWikipediaが「フリー百科事典」と称していることに起因しています。Wikipediaでは百科辞典をどのように位置付けているのでしょうか。以下に『Wikipedia:ガイドブック 編集方針』(https://ja.wikipedia.org/wiki/Wikipedia:ガイドライン)に書かれているものを紹介します。
『ところで、百科事典は国語辞典や字書(字典)などとはどう違うのでしょうか。辞書や用語集は、言葉の意味や定義を説明するものです。もちろん、意味を説明するためにその言葉の背景にも言及しなければならないこともあるでしょうが、それは補助的に行われるだけで、本来の目的ではありません。対して、百科事典は世の中のあらゆる事象を理解するための解説を提供することを目的としています。』
百科事典の分かり易さは、「定義」ではなく「解説」であることの恩恵です。ネット検索は膨大な情報の蓄積から必要な「定義」を探し出し、その「定義」を検索者が自分の脳を動かして、検索する背景などを踏まえた「解説」に昇華させて活用しているとモデル化できます。こう考えると生成AIは、膨大なネット上の情報(単独だけではなく関連する複数の情報も含め)を、その得意とする文書生成能力を駆使して、検索者に「定義」ではなく「解説」の形で提示してくれていると捉えることも出来ます。さらに、Wikipediaは誰もが加筆・編集できることで、参加した人それぞれが持つ「知」のシナジーを生み出しています。生成AIは"一人"ですが、人間の学習よりも格段に速く、格段に膨大で、格段に多様であることで多くの人の「知」のシナジーを生み出していることに匹敵します。別の観点でもWikipediaとの類似性を見ることが出来ます。それは情報の精度です。Wikipediaでは、執筆内容が間違っていることを、悪意や偏見などが無い限り否定はしていません。その間違いは、別の人が善意を持って修正していくことで全体としての信憑性を担保しています。ということは、過渡期には間違った情報(解説)が存在することが前提です。Wikipediaの黎明期はこのことがなかなか理解されず、Wikipediaの記載そのまま使うことで痛い思いをした人も多くいましたが、今はこの前提を踏まえて多くの人が利活用しています。生成AIも同様の道筋を辿ることは可能だし、辿らなくてはならないと思います。
巷での生成AIの取り上げられ方が「ゼロイチでの人との比較」、すなわち「人の(全面的な)代わりとなるか」的なものが多いのも懸念です。「人が生成するものと比べてどうか?」「生成AIが生成したものが著作権を侵害するのでは?」「生成AIが間違った結果を返すのは如何なものか」・・・このような生成AIを単体で評価することは危険です。Wikipediaの"仕組み"を適性に組み込んだ"仕掛け"の中で、我々は有効な活用をしているように、生成AIも適切な"仕掛け"にきちんと組み込んで活用することが必要です。"仕組み"だけではなく、使う人側のリテラシーや環境(規則や文化など)も含めた"仕掛け"の領域で考えることが求められているはずです。Wikipediaはポリシーやガイドブックなど膨大なガイドラインを用意しています。また、生成AIは訊ね方がキモとも言われ、「プロンプト エンジニア」なる人財の育成が必要との議論もあります。生成AIをはじめとする成長著しいITとひとが、最適なパートナーとして共存していくために、立体的な観点・視点を常に意識して行動することが求められています。
ちなみに、このコラムは生成AIの生成ではありません・・・

技術士(電気・電子部門)
永倉正洋 技術士事務所 代表
一般社団法人 人材育成と教育サービス協議会(JAMOTE)理事
1980年 日立製作所入社。
システム事業部(当時)で電力情報、通信監視、鉄道、地域活性化などのシステムエンジニアリングに取り組む。
2003年 情報・通信グループ アウトソーシング事業部情報ユーティリティセンタ(当時)センタ長として、情報ユーティリティ型ビジネスモデル立案などを推進。
2004年 uVALUE推進室(当時)室長として、情報・通信グループ事業コンセプトuVALUEを推進。
2006年 uVALUE・コミュニケーション本部(当時)本部長としてuVALUEの推進と広報/宣伝などを軸とした統合コミュニケーション戦略の立案と推進に従事。
2009年 日立インフォメーションアカデミー(当時)に移り、主幹兼研究開発センタ長としてIT人財育成に関する業務に従事。
2010年 企画本部長兼研究開発センタ長として、人財育成事業運営の企画に従事。
2011年 主幹コーディネータとしてIT人財に求められる意識・スキル・コンピテンシーの変化を踏まえた「人財育成のための立体的施策」立案と、 組織・事業ビジョンの浸透、意識や意欲の醸成などの講演・研修の開発・実施に従事。
2020年 日立アカデミーを退社。
永倉正洋技術士事務所を設立し、情報通信技術に関する支援・伝承などに取り組む。日立アカデミーの研修講師などを通じて、特に意識醸成、意識改革、行動変容などの人財育成に関する立体的施策の立案と実践に力点を置いて推進中。
お問い合わせ